Ollama + Open WebUI,快捷部署AI大模型到电脑,并离线执行
什么是ollama

Ollama 是一个开源软件,让用户可以在自己的硬件上运行、创建和分享大型语言模型服务。这个平台适合希望在本地端运行模型的使用者,因为它不仅可以保护隐私,还允许用户通过命令行界面轻松地设置和互动。Ollama 支持包括 Llama 2 和 Mistral 等多种模型,并提供灵活的定制选项,例如从其他格式导入模型并设置运行参数。
自从chatgpt出世以来,世界上各个大模型就像雨后春笋一般,遍地开花。但是无独有偶的是每一个大模型都是需要注册他们的账号,或网页端,或app中接受他们提供的服务。
我们自己要如何在本地使用这些大模型呢。ollama就在这时孕育而生了。只需要一道指令便可以轻松运行大模型。
下面我们将从ollama+图形界面Open WebUI来实现本地运行类chatgpt服务。
安装ollama
首先我们需要到ollama官网下载该软件,或者github中https://github.com/ollama/ollama
Ollama支持Linux、macOS、Windows、Raspberry Pi OS。
建议电脑至少CPUi5七代以上,RAM 8GB以上再使用Ollama。
因为Ollama使用llama.cpp技术,所以不需要独立GPU也能跑。不过有独立GPU更好,可以将一些模型层offload给GPU加速运算。
根据指引下载ollama完成安装之后,可以在cmd查看是否成功安装了ollama
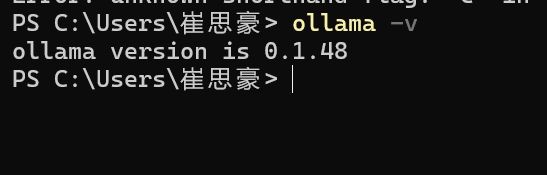
这里我安装是0.1.48版本 如果不小心关闭了ollama程序,输入ollama serve即可重新启动ollama服务,ollama自带运行日志管理。
部署open-webui
Open WebUI 是一种可扩展、功能丰富且用户友好的自托管 WebUI,旨在完全离线运行。它支持各种LLM运行器,包括 Ollama 和 OpenAI 兼容的 API。
地址:https://github.com/open-webui/open-webui/tree/main
我这里是使用docker来进行安装的,如果本机没有docker的话请自行去下载docker 地址:https://www.docker.com/products/docker-desktop/ docker安装完成之后,只需要open-webui官方提供的安装方法进行安装即可
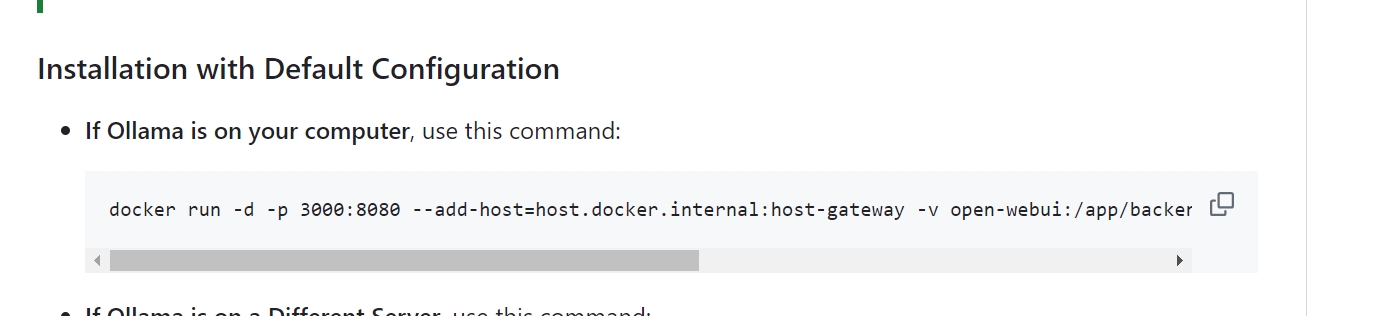
因为我本机已经安装了ollama 所以直接在cmd中执行
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
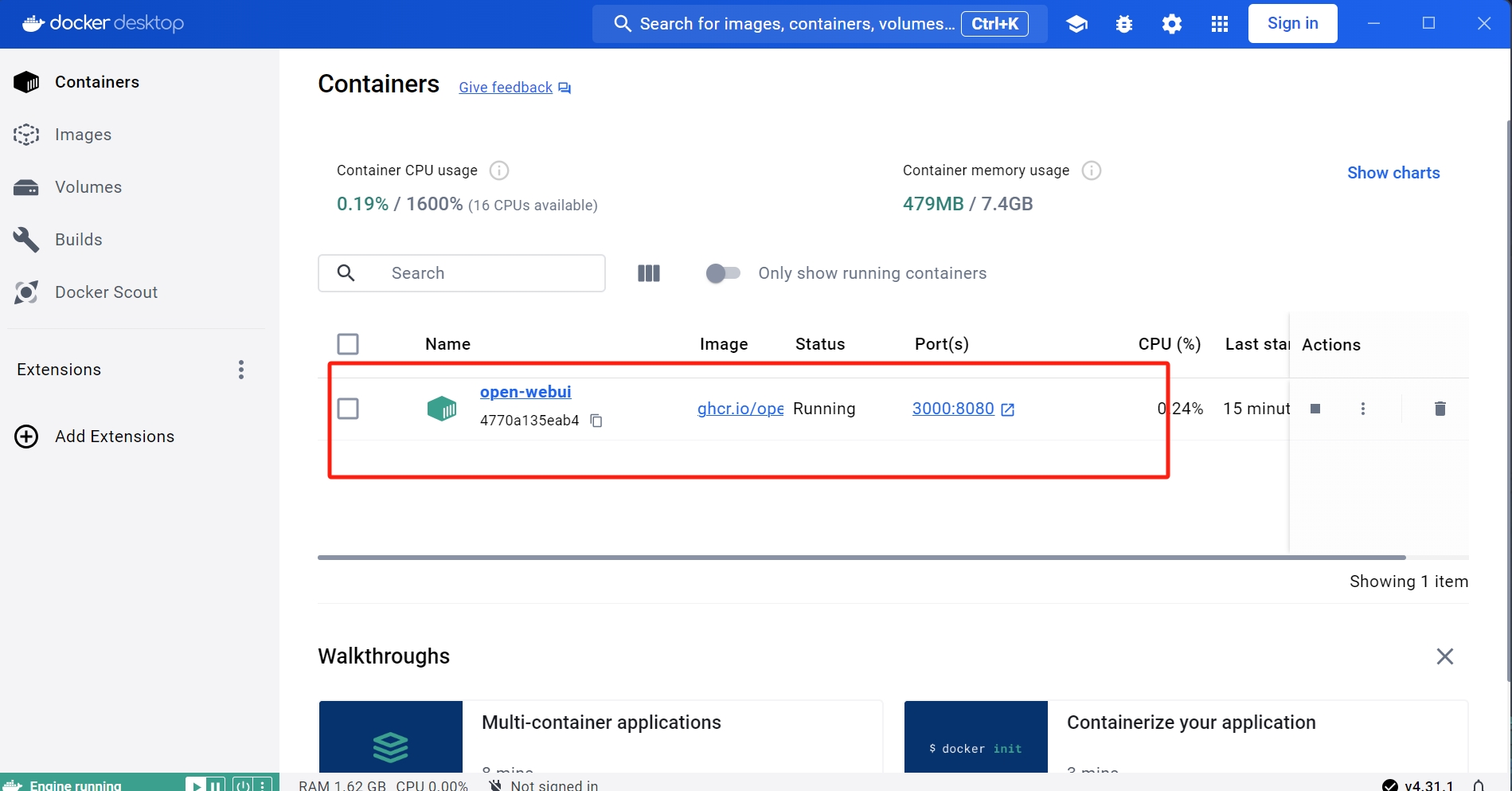
这个时候在docker desktop的Images中就能看到下载的open webui了
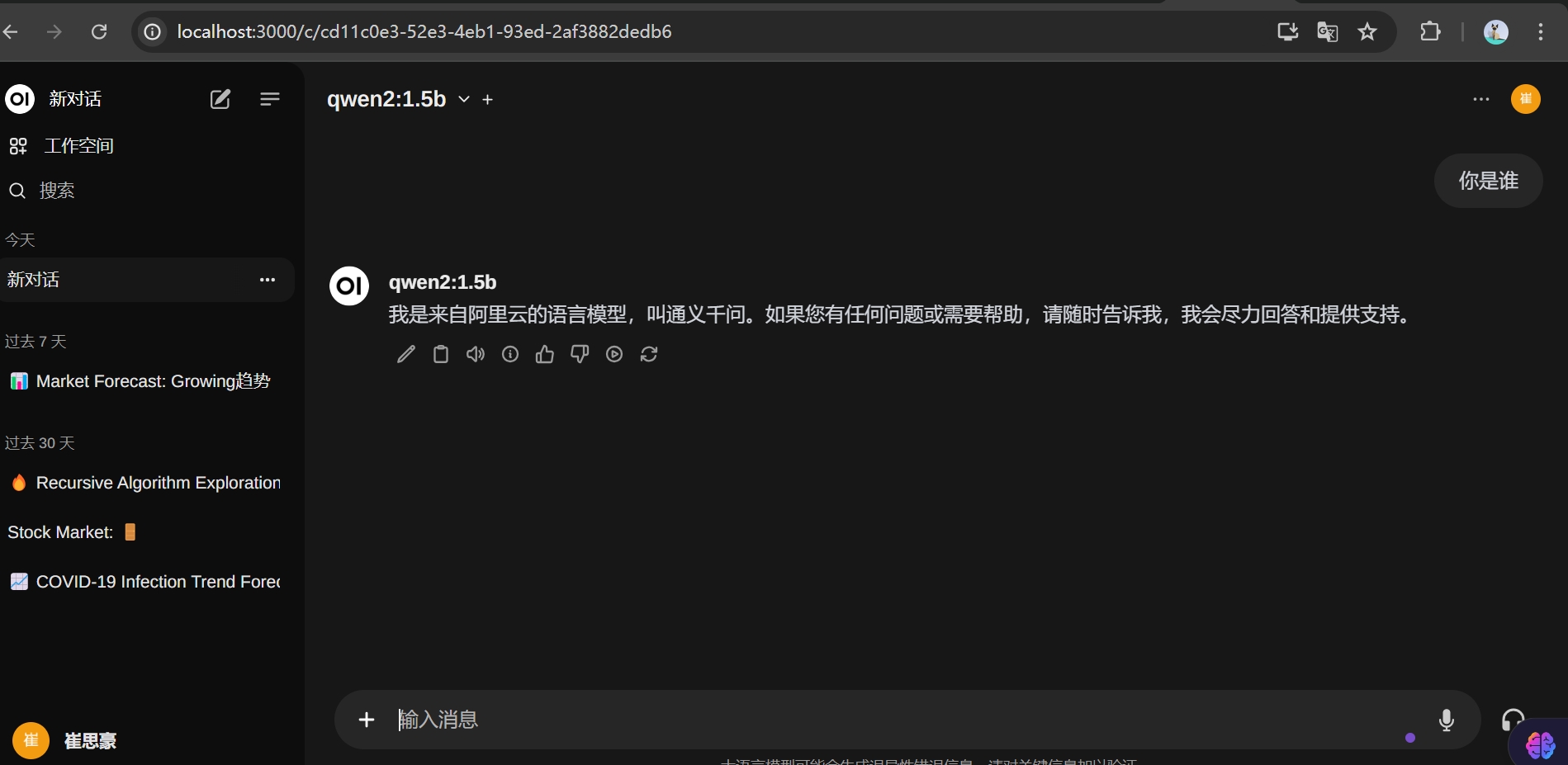
加载大模型
我们在docker中点击run启动open-webui项目后在浏览器中输入http://localhost:3000/即可进入
open-webui本身支持各种语言,英语困难的小伙伴也不用担心。点击右上角我的,设置里面可以选择语言,和主题风格。
设置语言之后,我们在下面的管理员设置中可以管理我的大模型
但是本人不建议在这里去下载我们的大模型,因为在这里下载会遇到卡在百分之99的情况。来自某人的教训。我们可以使用ollama提供的命令交互的方式去加载我们的大模型。
我们只需要在终端执行 便可以加载我们需要的大模型
ollama run llama3:8b
当然我们可以在ollama中选择我们想要下载那些大模型 https://ollama.com/library
当我们加载完成大模型之后,我们就可以在本地愉快的和大模型进行对话了。